Author: Hang Yu | Suofei Zhang
Email: hangyu5 at illinois.edu | zhangsuofei at njupt.edu.cn
Introduction to Capsule
Capsule can be perceived as an extension of perceptron. A capsule is able in take an tensor as input and output an another tensor. The output tensor is called a pose. The activation of an capsule is usually the norm of a certain dimension of the pose, or it could be generated independently for this pose alone. The activation represents the existence of certain feature. A capsule layer carries both the pose and its activation to the next capsule layer.
A deeper capsule doesn’t just simply read the output of a previous capsule layer. The poses and activations have to walk through a unsupervised learning procedure called “routing by agreement”. It allows training to learn from the distribution of input values by taking advantage of unsupervised learning methods. So that the training (i.e. supervised learning, e.g. image classification) is not longer dictated by the loss function alone, meaning the loss function (defined by us) and the data (defined by nature, collected by us) together contribute to the learning process.
However, even though the capsule is a more exciting algorithm than its counterpart CNN. The CNN baseline is well implemented mostly which enables it to train faster in the physical world than the capsule net. We will leave the discussion to expert in this field.
Abstract, introduction and contribution of [1] can be found in its paper. Details for our implementation can be found in [2].
Code of Conduct
From ICLR 2018 Reproducibility challenge:
Participants should produce a Reproducibility report, describing the target questions, experimental methodology, implementation details, analysis and discussion of findings, conclusions on reproducibility of the paper. This report should be posted as a contributed review on OpenReview.
The result of the reproducibility study should NOT be a simple Pass / Fail outcome. The goal should be to identify which parts of the contribution can be reproduced, and at what cost in terms of resources (computation, time, people, development effort, communication with the authors).Participants should expect to engage in dialogue with ICLR authors through the OpenReview site. In cases where participants have made significant contributions to the final paper, ICLR should allow adding these participants as co-authors (at the request of the original authors only.)
Reproduce Method
Hyperparameters
smallNORB dataset:
- Samples per epoch: 46800
- Sample dimensions: 96x96x1
- Batch size: 50
- Preprocessing:
- training:
- add random brightness with max delta equals 32 / 255.
- add random contrast with lower 0.5 and upper 1.5.
- resize into HxW 48x48 with bilinear method.
- crop into random HxW 32x32 piece.
- apply batch norm to have zero mean and unit variance.
- squash the image from 4 so that each entry has value from 0 to 1. This image is to be compared with the reconstructed image.
- testing:
- resize into HxW 48x48 with bilinear method.
- crop the center HxW 32x32 piece.
- apply batch norm with moving mean and moving variance collected from training data set.
- training:
Method
The so called dynamic routing is in analog to the fully-connected layer in CNN. The so called ConvCaps structure extends dynamic routing into convolutional filter structure. The ConvCaps are implemented similarly as the dynamic routing for the whole feature map. The only difference is to tile the feature map into kernel-wise data and treat different kernels as batches. Then EM routing can be implemented within each batch in the same way as dynamic routing.
Different initialization strategies are used for convolutional filters. Linear weights are initialized with Xavier method. Biases are initialized with truncated normal distribution. This configuration provide higher numerical stability of input to EM algorithm.
The output of ConvCaps2 layer is processed by em routing with kernel size of 1*1. Then a global average pooling is deployed here to results final Class Capsules. Coordinate Addition is also injected during this stage.
Equation 2 in E-step of Procedure 1 from original paper is replaced by products of probabilities directly. All the probabilities are normalized into [0, 10] for higher numerical stability in products. Due to the division in Equation 3, this operation will not impact the final result. Exponent and logarithm are also used here for the same purpose.
A common l2 regularization of network parameters is considered in the loss function. Beside this, reconstruction loss and spread loss are implemented as the description in the original paper.
Learning rate: starts from 1e-3, then decays exponentially in a rate of 0.8 for every 46800/50 steps, and ends in 1e-5 (applied for all trainings).
We use Tensorflow 1.4 API and python programming language.
Reproduce Result
Overview
Experiments on is done by Suofei Zhang. His hardware is:
- cpu:Intel(R) Xeon(R) CPU E5-2680 v4@ 2.40GHz,
- gpu:Tesla P40
On test accuracy:
smallNORB dataset test accuracy (our result/proposed result):
- CNN baseline (4.2M): 88.7%(best)/94.8%
- Matrix Cap with EM routing (310K, 2 iteration): 91.8%(best)/98.6%
There are two comments to make:
- Even though the best of Matrix Cap is over by 3% to the best of CNN baseline, the test curve suggest Matrix Cap fluctuates between roughly 80% to 90% test dataset.
- We are curious to know the learning curve and test curve that can be generated by the author.
Training speed:
- CNN baseline costs 6m to train 50 epochs on smallNORB dataset. Each batch costs about 0.006s.
- Matrix Cap costs 15h55m36s to train. Each batch costs about 1.2s.
Recon image:
Will come soon.
routing histogram:
We have difficulty in understanding how the histogram is calculated.
AD attack:
We haven’t planned to run AD attack yet.
Notes
Status:
According to github commit history, this reproduce project had its init commit on Nov.19th. We started writing this report on Dec.19th. Mainly, it is cost by undedicated code review so that we have to fix bug and run it again, otherwise the project should be able to finish in a week.Current Results on smallNORB:
- Configuration: A=32, B=8, C=16, D=16, batch_size=50, iteration number of EM routing: 2, with Coordinate Addition, spread loss, batch normalization
- Training loss. Variation of loss is suppressed by batch normalization. However there still exists a gap between our best results and the reported results in the original paper.
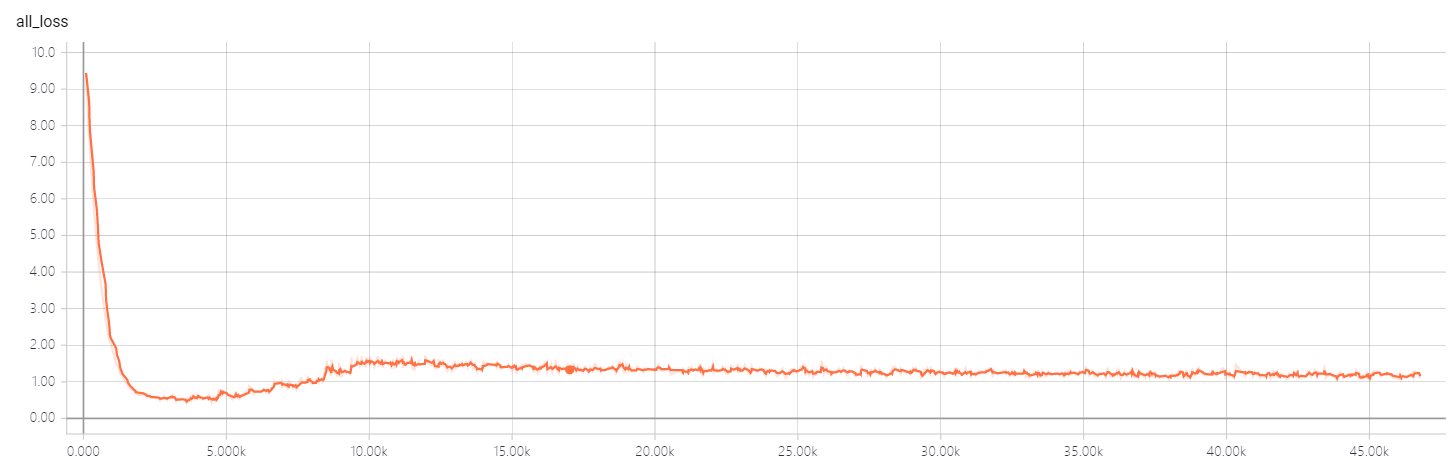
- Test accuracy(current best result is 91.8%)
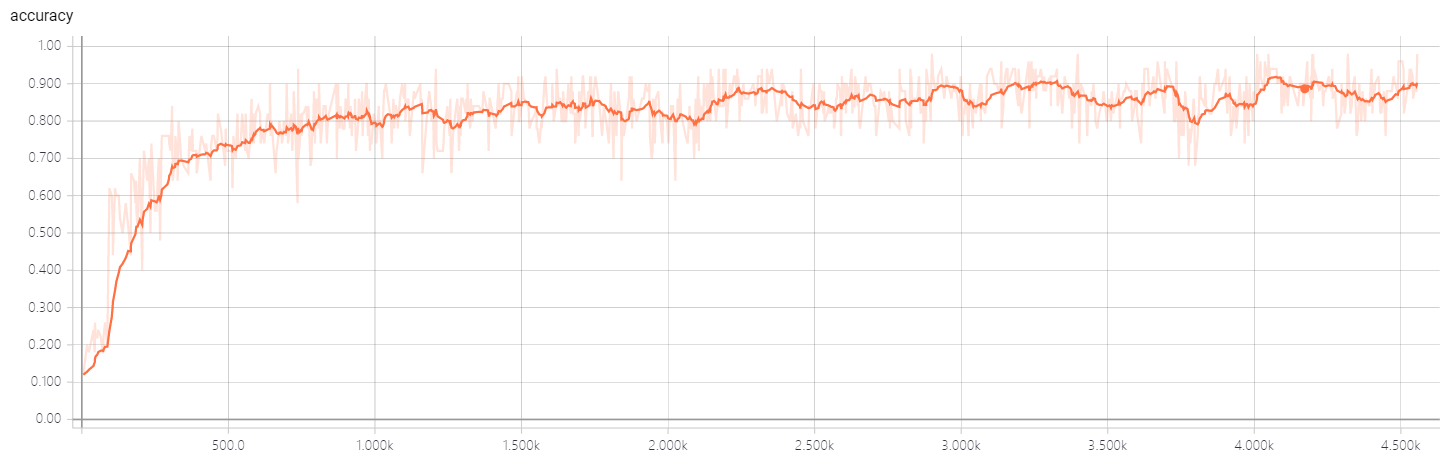
Ablation Study on smallNORB:
- Configuration: A=32, B=8, C=16, D=16, batch_size=32, iteration number of EM routing: 2, with Coordinate Addition, spread loss, test accuracy is 79.8%.
Current Results on MNIST:
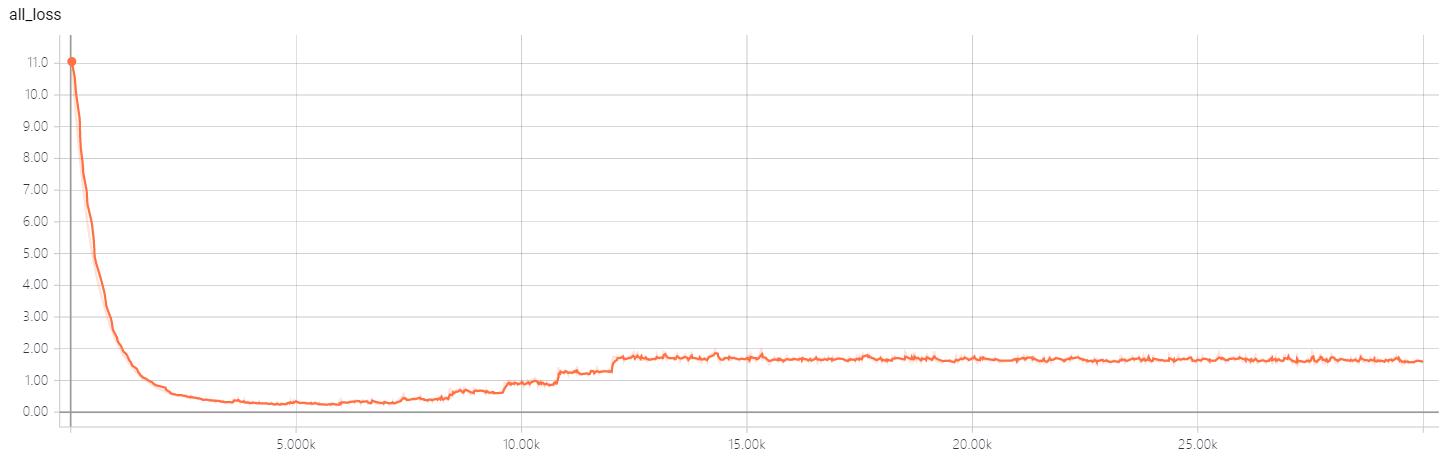
- Configuration: A=32, B=8, C=16, D=16, batch_size=50, iteration number of EM routing: 2, with Coordinate Addition, spread loss, batch normalization, reconstruction loss.
Training loss.
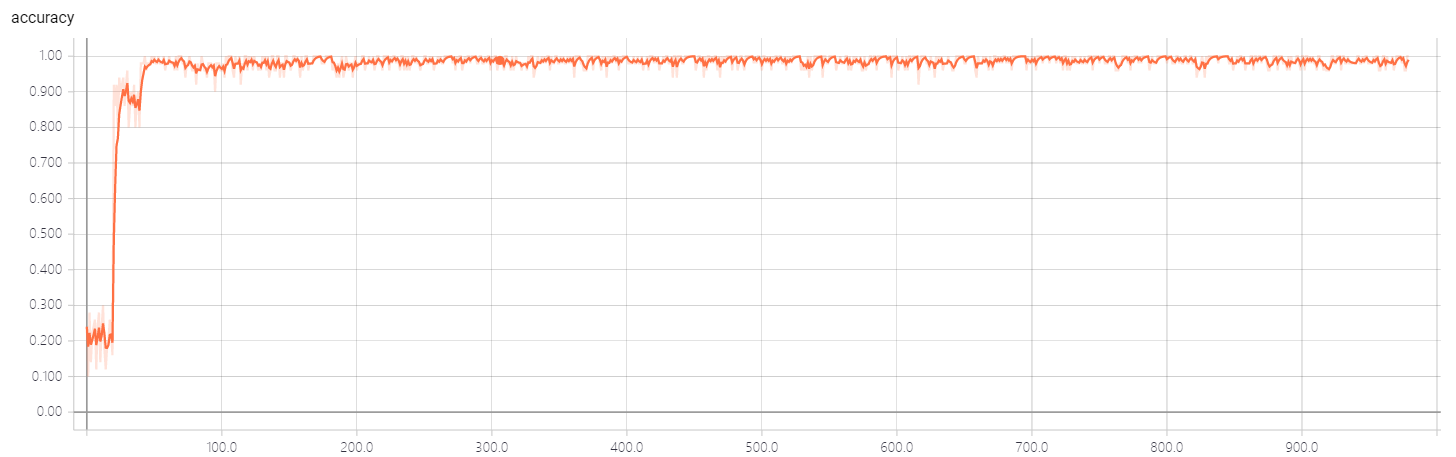
Test accuracy(current best result is 99.3%, only 10% samples are used in test)
##Reference
[1] MATRIX CAPSULES WITH EM ROUTING (paper)
[2] Matrix-Capsules-EM-Tensorflow (our github repo: code and comments)